mode: normal, opacitat 100%, Fluxe: 100% suavitzar: 100%
O EN CAPES:

mode: normal, opacitat 100%, Fluxe: 100% suavitzar: 100%
O EN CAPES:
Aquest script està fet en Bash (Bourne Again Shell), que és el llenguatge de scripting per defecte en la majoria de sistemes Linux/Unix, incloent-hi el Synology DSM.
backup_polidic.sh
==================
#!/bin/bash
# sudo chmod +x /usr/local/bin/backup_polidic.sh
# sudo cp /volume2/web/backup_polidic.sh /usr/local/bin/
# sudo chmod +x /usr/local/bin/backup_polidic.sh //executa
# sudo sed -i 's/\r$//' /usr/local/bin/backup_polidic.sh --> ELIMINA ELS RETORN DE CARRO
# sudo chmod +x /usr/local/bin/backup_polidic.sh --> COMPROVA QUE SEGUEIX SENT EXECUTABLE
# Llista de bases de dades a copiar (separades per espais)
DB_LIST=("polidic_por" "polidic_cat" "encara_una_mes")
DB_USER="root"
DB_PASS="B*********!"
BACKUP_DIR="/volume2/MySQL_backup/polidic"
DATE=$(date +"%Y-%m-%d_%H-%M")
# Comprovar que la carpeta existeix
if [ ! -d "$BACKUP_DIR" ]; then
echo "ERROR: El directori $BACKUP_DIR no existeix."
exit 1
fi
# Bucle per cada base de dades
for DB_NAME in "${DB_LIST[@]}"; do
FILE="$BACKUP_DIR/${DB_NAME}_$DATE.sql.gz"
echo "Fent backup de la base de dades: $DB_NAME..."
mysqldump -u"$DB_USER" -p"$DB_PASS" "$DB_NAME" | gzip > "$FILE"
if [ $? -eq 0 ]; then
echo "Backup complet: $FILE"
else
echo "ERROR durant el backup de $DB_NAME"
fi
done
comprovem:
ls -l /volume2/web/backup_polidic.sh
ls -l /volume2/web/backup_beseit.sh
sudo /usr/local/bin/backup_polidic.sh // executa el script
ls -l /usr/local/bin/backup_polidic.sh // comprova el directori i privilegis
Si l’escrip ja está instal·lat entrem:
Des de Windows obrim Powershell com administrador
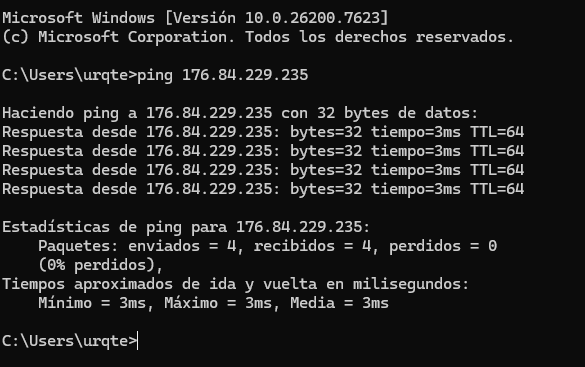
PS C:\WINDOWS\system32> ssh urqtejmi@192.168.1.41
urqtejmi@192.168.1.41’s password:
Codi
ssh urqtejmi@192.168.1.41
Comprovar que l’script funciona manualment (opcional)
sudo /usr/local/bin/backup_polidic.sh
Elimina els retorn de carro:
sudo sed -i 's/\r$//' /usr/local/bin/backup_polidic.sh
dona permisos d’execució:
sudo chmod +x /usr/local/bin/backup_polidic.sh
find /volume2 -name "*.sql" -mtime +7 -delete (troba i esborra fitxers antics) és molt més directe que fer-ho en un llenguatge d’alt nivell.|):
mysqldump ... | gzip > fitxer.sql.gz. Això fa un backup i el comprimeix al vol, sense crear fitxers temporals gegants.mysqldump, curl, ssh, rsync, etc., i coordinar-les.+x ja és un programa executable.
Perfecte, Miquel. Afegim aquest punt extra perquè és molt important per mantenir l’script net, segur i fàcil de mantenir. I ja que vols un resum escuet i consolidat, t’ho deixo tot plegat en un checklist compacte i molt operatiu.
PowerShell (Administrador):
PS C:\WINDOWS\system32> Get-Service sshd
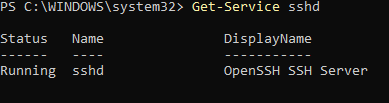
Get-Service sshd
Ha de sortir Running i Automatic.
Get-NetFirewallRule -DisplayName "OpenSSH Server (TCP-In)"
Si no existeix, crear-lo.
Des d’un altre dispositiu:
ssh NOM_USUARI_WINDOWS@IP_DEL_WINDOWS
Des de Windows:
ssh urqtejmi@192.168.1.41
Si entres i veus el prompt del Synology, tot correcte.
Dins del Synology:
ls -l /usr/local/bin/backup_polidic.sh
Ha de sortir:
-rwx------ 1 root root ...
ls -l /volume2/MySQL_backup/polidic
sudo /usr/local/bin/backup_polidic.sh
Aquest és el punt que volies afegir, i és molt encertat.
/usr/local/bin/backup_polidic.sh.És millor editar la còpia de treball a:
/volume2/web/backup_polidic.sh
Perquè:
/usr/local/bin, que és més delicatsudo cp /volume2/web/backup_polidic.sh /usr/local/bin/ && \
sudo sed -i 's/\r$//' /usr/local/bin/backup_polidic.sh && \
sudo chmod +x /usr/local/bin/backup_polidic.shsudo cp /volume2/web/backup_beseit.sh /usr/local/bin/ && \
sudo sed -i 's/\r$//' /usr/local/bin/backup_beseit.sh && \
sudo chmod +x /usr/local/bin/backup_beseit.shAixò executa:
sudo cp /volume2/web/backup_polidic.sh /usr/local/bin/ sudo chmod +x /usr/local/bin/backup_polidic.sh sudo sed -i 's/\r$//' /usr/local/bin/backup_polidic.sh
Això garanteix:
És un esquema simple, robust i fàcil de revisar sempre que calgui.
Si vols, puc preparar-te aquest checklist en format PDF, Markdown, o fins i tot com a script de comprovació automàtica al Synology.
Pasword router:
wifi: movistar_430 pasword: iqxe6GFLio4zD32fYNQk
| c 1,1 | c 1,2 |
 | c 2,2 |
Posarem la imatge: Imagen3.png (567×374)
| c0,1 |  |
És una d’aquelles coses que hauria de ser fàcil, però Gutenberg no té (encara) un bloc de taula tan flexible com un editor tipus Word. Tot i així, es pot fer perfectament. Aquí tens la manera més clara i fiable de posar una imatge a la cel·la 1,1 d’una taula 2×1.
Això et crearà una taula amb:
Fes clic dins de la primera cel·la (la de l’esquerra). Veureu el cursor parpellejant dins la cel·la.
Tens dues opcions:
Gutenberg permet blocs dins de cel·les, així que un bloc Imatge funciona perfectament.
Gutenberg la convertirà automàticament en un bloc Imatge dins la cel·la.
Si la imatge no s’ajusta bé:

| c1,1 | c1,2 |
| c2,1 | c22 |
Si vols, puc explicar-te també com fer que la taula sigui responsive, o com centrar verticalment la imatge dins la cel·la.
Windows 10 i 11, encara que desactivis “Protecció en temps real”, Microsoft Defender continua funcionant en segon pla. No s’apaga del tot, només es “relaxa” temporalment. I quan veu un fitxer que considera sospitós, l’elimina igualment.
✔️ La solució real per inhibir-lo: crear una exclusió
Això sí que funciona i és permanent:
.exeA partir d’aquí, Defender no tocarà res dins d’aquesta carpeta, encara que el detecti com a sospitós.
✔️ Què has de fer exactament
.exe concret.A partir d’aquí, Defender no eliminarà el programa, perquè l’exclusió té prioritat.
https://www.google.com/search?q=inhibit+Windows+defender+from+PowerShellSet-MpPreference -DisableRealtimeMonitoring $true
Codi
Add-MpPreference -ExclusionPath "C:\Ruta\A\La\Carpeta"
També pots excloure un fitxer concret:
Add-MpPreference -ExclusionProcess "C:\Ruta\Programa.exe"
O excloure una extensió sencera:
Add-MpPreference -ExclusionExtension ".exe"
El broker et presta l’actiu (no et dona diners) (encara que ni tu ni el broker toca mai lor)
Exemple: El broker et presta 1 onça d’or que ell mateix posseeix o obté d’un altre client.
Tu vens immediatament aquest actiu al mercat
Vens l’onça d’or al preu actual (per exemple, $5.000) i reps aquests diners al teu compte.
Mantes una obligació: retornar l’actiu
No has de retornar diners, sinó 1 onça d’or física (o equivalent en el mercat) al broker en el futur.
Tancament de la posició
Si l’or baixa a $4.500: compres 1 onça a aquest preu, la retornes al broker i guanyes $500 (menys comissions i costos de préstec).
Sí, absolutament. Els grans jugadors institucionals (bancs d’inversió, hedge funds, market makers, fonds de pensiones) utilitzen àmpliament trading algorísmic i robots de negociació —de fet, aquesta és la norma, no l’excepció.
| Mercat | % Volum aprox. algorísmic (2025–2026) | Actors principals |
|---|---|---|
| Accions (EUA/Europa) | 60–75% | Citadel Securities, Virtu, Jane Street, bancs (Goldman, JPM) |
| Futurs de metalls preciosos (COMEX) | 50–70% | Jump Trading, DRW, bancs amb desks de commodities |
| Criptomonedes | 70–85% | Market makers institucionals (Wintermute, GSR), HFT shops |
| Divises (FX) | 80%+ | Bancs (Deutsche Bank, Citi), algotraders especialitzats |
Font: Estimacions de Bloomberg Intelligence, TABB Group i informes de borses (CME, NYSE) 2025–2026.
| Tipus | Funció | Exemple pràctic |
|---|---|---|
| HFT (High-Frequency Trading) | Executa milers d’ordres per segon per capturar micro-spreads | Un algoritme detecta que l’or a COMEX és $0.05 més barat que a Londres i executa arbitratge en <1 ms |
| Execution algorithms | Divideix grans ordres per minimitzar impacte al mercat | Un banc ha de vendre 10.000 lots d’or: l’algoritme ho fa en porcions petites durant hores per no moure el preu |
| Statistical arbitrage | Detecta desviacions estadístiques entre actius correlats | Si l’or puja però la plata no segueix el patró històric, l’algoritme compra plata/vend or esperant convergència |
| Market making | Proporciona liquiditat constant amb ordres bid/ask | Un robot manté ordres de compra/venda d’or a 0.1% de spread, guanyant per volum |
Sí, els algoritmes van jugar un paper clau:
⚠️ Important: Això no implica «manipulació». Són respostes automàtiques a senyals de mercat —però la seva velocitat i escala amplifiquen les caigudes inicials, creant flash crashes.
| Retail (particulars) | Institucionals |
|---|---|
| Majoritàriament manual o semi-automàtic (scripts senzills) | 100% algorísmic en operacions significatives |
| Latència: segons/minuts | Latència: microsegons (fibra òptica directa a servidors de borsa) |
| Volum: lots individuals | Volum: milers de lots simultanis |
Sí, els grans jugadors no operen manualment en mercats líquids com l’or, la plata o el bitcoin. El 60–85% del volum diari és generat per algoritmes que prenen decisions en mil·lisegons. Això no és «trampa»: és la realitat dels mercats moderns. Però aquesta automatització també fa que les caigudes inicials es propaguin exponencialment —com vam veure el 30 de gener de 2026.
Una crida de marge (margin call) és una notificació obligatòria del broker que et demana que aportis més diners o actius al teu compte per mantenir una posició apalancada oberta. Si no ho fas en el termini establert, el broker tanca automàticament la teva posició (sovint amb pèrdues).
Quan operes amb apalancament, no pagues el 100% del valor de l’actiu. En lloc d’això, el broker et presta una part i tu només has de posar una garantia inicial (el marge inicial).
Exemple:
El broker exigeix que mantinguis un marge mínim (per exemple, el 5% del valor de la posició). Si el preu es mou en contra teva i el valor de la teva garantia cau per sota d’aquest llindar, s’activa la crida.
| Concepte | Valor |
|---|---|
| Posició: 100 oz d’or a $5.000/oz | $500.000 |
| Marge inicial (10%) | $50.000 |
| Marge mínim requerit (5%) | $25.000 |
| Preu cau a $4.800/oz | → Valor posició = $480.000 |
| Pèrdua no realitzada | $20.000 |
| Garantia restant ($50.000 – $20.000) | $30.000 ✅ (encara per sobre del mínim) |
| Preu cau a $4.700/oz | → Valor posició = $470.000 |
| Pèrdua no realitzada | $30.000 |
| Garantia restant ($50.000 – $30.000) | $20.000 ❌ (per sota del mínim de $25.000) |
➡️ Resultat: El broker et notifica una margin call. Has de dipositar almenys $5.000 addicionals en minuts/hores, o bé tancarà automàticament la teva posició.
| Concepte | Què passa |
|---|---|
| Crida de marge | Notificació: «Aporta més garanties o tancaré la posició». Hi ha un breu termini (minuts a hores) per actuar. |
| Liquidació automàtica | Si ignores la crida o el moviment és massa ràpid (com el 30/01/2026), el broker tanca la posició sense avís previ per protegir-se de pèrdues majors. |
⚠️ En mercats molt volàtils (com el divendres 30 de gener), les crides de marge es converteixen instantàniament en liquidacions automàtiques perquè els preus canvien en mil·lisegons —no hi ha temps per reaccionar.
Aquell dia:
Això és el que va provocar caigudes del 11% en l’or i fins al 33% en la plata en poques hores.
Preu estable → Garantia > Marge mínim → ✅ Posició oberta
↓
Preu cau → Garantia ≈ Marge mínim → ⚠️ CRIDA DE MARGE (has d'aportar diners)
↓
Preu cau més → Garantia < Marge mínim → ❌ LIQUIDACIÓ AUTOMÀTICA (pèrdua realitzada)
En essència: una crida de marge és el mecanisme de seguretat del broker per evitar que tu li deus diners. Però en mercats extrems, aquest mecanisme es converteix en el detonant de caigudes en cascada.
Sí, absolutament. En l’actualitat, les crides de marge són totalment automatitzades i generades per sistemes informàtics (risk engines) del broker o de la borsa —sense intervenció humana en el 99,9% dels casos.
graph LR
A[Monitoratge en temps real<br>del marge de cada compte] --> B{Marge < llindar mínim?}
B -- Sí --> C[Algoritme activa crida de marge]
C --> D1[Notificació automàtica<br>(email/SMS/push)]
C --> D2[Bloqueig de noves ordres]
C --> D3[Comptador de temps<br>(ex: 5 minuts)]
D3 --> E{Garanties reposades?}
E -- No --> F[Liquidació automàtica<br>de posicions]
E -- Sí --> G[Posició mantinguda]
| Element | Realitat |
|---|---|
| Velocitat | El sistema detecta i actua en mil·lisegons —més ràpid que qualsevol humà. |
| Escalabilitat | Un sol algoritme pot gestionar milions de comptes simultàniament (ex: Interactive Brokers té >1,5M de clients actius). |
| Decisió | Basada en regles matemàtiques simples: marge_actual / valor_posició < llindar → crida. Cap «judici» humà. |
| Execució | La liquidació automàtica es fa enviant ordres de venda directament al mercat —sovint via API HFT. |
Només en casos extremadament específics hi ha intervenció humana:
Per a traders retail (particulars) o fins i tot traders professionals amb comptes < $1M, mai hi ha un humà al circuit —tot és robotitzat.
⚠️ En molts casos, els traders no van rebre ni la notificació abans que les seves posicions fossin liquidades —el procés va ser més ràpid que el temps de transmissió d’un SMS o email.
Sí, una crida de marge és 100% generada per un robot/algoritme. Això no és una opció: és una necessitat tècnica per gestionar el risc a escala i velocitat. Però aquesta mateixa automatització és el que converteix una correcció normal en una caiguda en cascada quan milers de sistemes actuen simultàniament —com vam veure amb l’or, la plata i el bitcoin el 30 de gener de 2026.
La garantia (margin) existeix per una raó fonamental: protegir al prestador (el broker) del risc de crèdit quan et presta diners per operar amb apalancament. És el «col·lateral» que assegura que podrà recuperar el seu capital encara que el mercat es mogui en contra teva.
Imagina aquest escenari sense garantia:
| Pas | Què passa |
|---|---|
| 1 | El broker et presta $450.000 per comprar or (tu aportes $0). |
| 2 | Compres 100 oz a $5.000/oz ($500.000 total). |
| 3 | El preu cau a $1.000/oz → la teva posició val ara $100.000. |
| 4 | Tens una pèrdua de $400.000. |
| 5 | Tanques la posició i… desapareix sense pagar el deute. |
➡️ Resultat: El broker perd $400.000 i tu et quedes amb la pèrdua sense conseqüències financeres directes (només la teva reputació creditícia). Això és insostenible per a qualsevol sistema financer.
La garantia és diners o actius que tu bloqueges al broker com a «assegurança» que cobrirà les pèrdues si el mercat es mou en contra teva.
| Concepte | Funció |
|---|---|
| Garantia inicial | Quantitat mínima que has de dipositar per obrir una posició apalancada (ex: 10% del valor). |
| Garantia de manteniment | Nivell mínim que ha de mantenir-se durant la vida de la posició (ex: 5%). Si cau per sota → margin call. |
| Operació apalancada | Hipoteca |
|---|---|
| Vols comprar or per $500.000 | Vols comprar una casa per $500.000 |
| El broker et presta $450.000 | El banc et presta $450.000 |
| Tu aportes $50.000 de garantia | Tu aportes $50.000 d’entrada |
| Si el preu cau → margin call | Si no pagues → embargament |
| El broker ven l’or per recuperar el préstec | El banc ven la casa per recuperar el préstec |
En ambdós casos, la garantia és el «darrer recurs» perquè el prestador recuperi el seu capital.
| Situació | Sense garantia | Amb garantia ($50.000) |
|---|---|---|
| Préstec del broker | $450.000 | $450.000 |
| Teva aportació | $0 | $50.000 (bloquejats) |
| Preu cau a $4.000/oz | Pèrdua: $100.000 → Impagament total | Pèrdua: $100.000 → Garantia esgota a $0 |
| Resultat per al broker | Perd $100.000 | Ven automàticament abans que la garantia arribi a $0 → recupera ~$440.000 |
➡️ La garantia limita la pèrdua màxima del broker al teu capital bloquejat.
La garantia existeix perquè ningú presta diners sense assegurança en un mercat volàtil. És el mecanisme que permet que:
És una protecció per a totes les parts —encara que, en moments de crisi extrema com el 30 de gener de 2026, aquesta protecció es converteix en el detonant de vendes massives que amplifiquen la caiguda. És la cara i creu de l’apalancament.