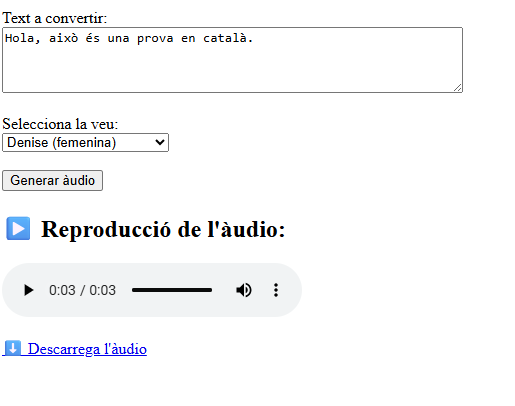
Script:
# Crear l'objecte de síntesi de veu
$speak = New-Object -ComObject SAPI.SpVoice
# Mostrar les veus disponibles
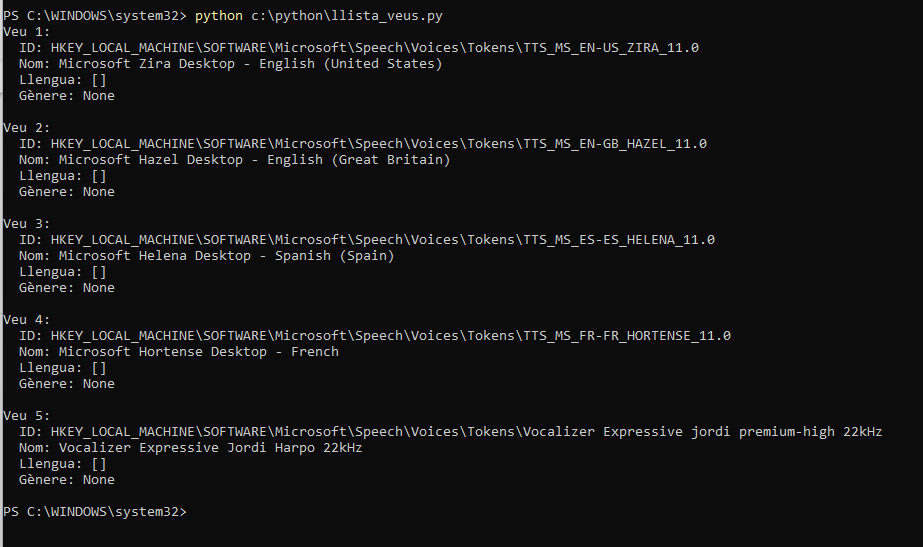
Write-Host "Veus disponibles:"
$voices = $speak.GetVoices()
for ($i = 0; $i -lt $voices.Count; $i++) {
Write-Host "$i - " $voices.Item($i).GetDescription()
}
# Seleccionar veu
$index = Read-Host "Introdueix el número de la veu que vols utilitzar"
$speak.Voice = $voices.Item($index)
# Entrada de text
$entrada = Read-Host "Introdueix el text que vols escoltar"
# Reproduir el text
$speak.Speak($entrada)
?️ Com executar-lo
- Obre PowerShell com a administrador.
- Enganxa el codi anterior.
- Se’t mostrarà la llista de veus disponibles.
- Introdueix el número corresponent a la veu que vols provar.
- Escriu el text que vols que es llegeixi.
- Aquest script accedeix a les veus SAPI, com Microsoft David Desktop, Zira Desktop, etc.
- Les veus Neural del Narrador (com JennyNeural, HelenaNeural) no són accessibles amb aquest mètode directe. Si vols, et puc preparar una versió amb WinRT per accedir a les veus OneCore.
Amb les veus del narrador:
Vols que et generi també la versió avançada amb WinRT per accedir a les veus del Narrador?
# Requereix Windows 10/11 i PowerShell 5.x o superior
Add-Type -AssemblyName System.Runtime.WindowsRuntime
$SynthType = [Windows.Media.SpeechSynthesis.SpeechSynthesizer]
$Synth = New-Object $SynthType
# Llistar veus disponibles
$voices = $Synth.AllVoices
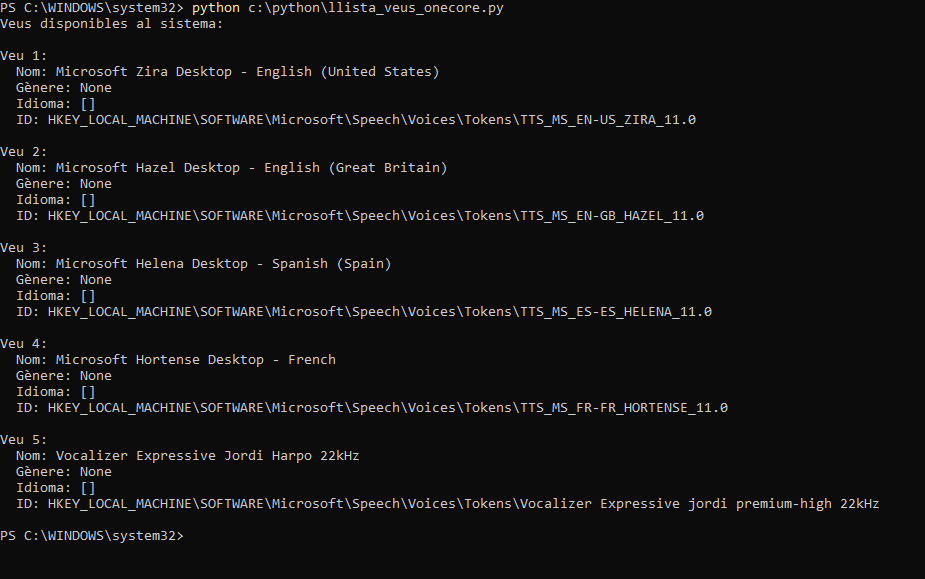
Write-Host "Veus OneCore disponibles:"
for ($i = 0; $i -lt $voices.Count; $i++) {
$voice = $voices[$i]
Write-Host "$i - $($voice.DisplayName) [$($voice.Language)]"
}
# Seleccionar veu
$index = Read-Host "Introdueix el número de la veu que vols utilitzar"
$Synth.Voice = $voices[$index]
# Entrada de text
$text = Read-Host "Introdueix el text que vols escoltar"
# Sintetitzar i reproduir
$stream = $Synth.SynthesizeTextToStreamAsync($text).GetAwaiter().GetResult()
$player = New-Object System.Media.SoundPlayer
$player.Stream = $stream.AsStream()
$player.PlaySync()
Com executar-lo
- Obre PowerShell com a administrador.
- Enganxa el codi anterior.
- Veuràs la llista de veus OneCore disponibles (amb nom i idioma).
- Introdueix el número de la veu que vols provar.
- Escriu el text que vols escoltar.