sds
D’acord, ara que tinc una visió general del sistema, em posaré a analitzar-lo component per component per donar-te una explicació detallada de com funciona aquest inversor híbrid solar. Començaré per la font d’energia i després seguiré el flux d’energia cap a les càrregues.
Primer, miraré de prop:
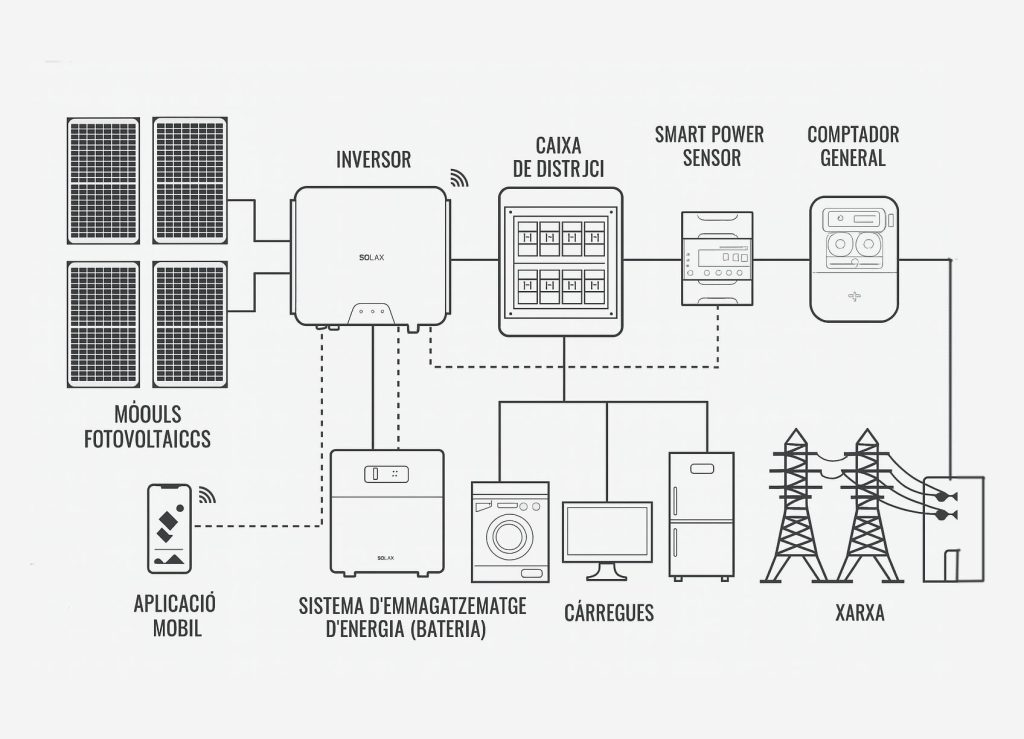
La imatge mostra clarament els MÒDULS FOTOVOLTAICS connectats a un INVERSOR. Aquests panells són els que capturen l’energia solar i la converteixen en corrent continu (DC). L’inversor és el component central que converteix aquesta energia DC en corrent altern (AC) utilitzable pels aparells domèstics. També veig que hi ha una connexió amb un SISTEMA DE ALMACENAMENT DE ENERGÍA (BATERIA), que permet emmagatzemar l’excés d’energia solar per utilitzar-la quan no hi ha sol o durant un tall de llum. El sistema també està connectat a la RED (xarxa elèctrica), cosa que significa que pot importar energia de la xarxa si cal i exportar-hi l’excés.
Per entendre millor el paper de cada component, aniré investigant-los un per un.
Segon, trobar informació:
Començaré per investigar què és exactament un inversor híbrid solar i com funciona en aquest tipus de configuració.
D’acord, ara veig clarament la part inicial del sistema. Aquesta imatge mostra els mòduls fotovoltaics (els panells solars) connectats directament a l’inversor. Els panells generen corrent continu (DC) a partir de la llum solar, i l’inversor és el component que converteix aquesta energia DC en corrent altern (AC), que és el tipus d’electricitat que utilitzen els nostres aparells domèstics.
El fet que hi hagi una icona de Wi-Fi a l’inversor suggereix que és un model intel·ligent, capaç de comunicar-se amb altres dispositius o aplicacions per monitoritzar el rendiment del sistema.
Ara, per entendre el funcionament complet del sistema híbrid, necessito veure com es connecta l’inversor amb la bateria i la xarxa. Aniré a mirar la resta del diagrama per veure aquestes connexions.
Perfecte, aquesta imatge em dóna una visió clara de la part final del sistema. Veig que l’energia AC generada per l’inversor va cap a la CAJA DE DISTRIBUCIÓN (quadre elèctric), que és el punt central on es distribueix l’electricitat a les diferents CÀRREGUES (com ara la màquina de rentar, el frigorífic i el monitor).
També veig que hi ha un SMART POWER SENSOR (sensor intel·ligent de potència) i un CONTADOR GENERAL connectats a la xarxa. Aquests dispositius són clau en un sistema híbrid, ja que permeten al sistema saber quanta energia està consumint la casa i quanta està disponible de la xarxa o de la bateria.
Per entendre com es gestiona tot aquest flux d’energia, necessito investigar el paper específic dels sensors i del comptador en un sistema fotovoltaic híbrid. Aniré a buscar informació sobre aquests components.
D’acord, ara tinc una visió completa del sistema. L’esquema mostra un sistema fotovoltaic híbrid ben integrat. Per explicar com funciona aquest inversor híbrid solar, cal entendre que no és només un dispositiu que converteix corrent continu en altern, sinó que és el «cervell» d’un sistema energètic intel·ligent que gestiona tres fonts d’energia: la solar, la de la bateria i la de la xarxa elèctrica.
Aquí tens una explicació detallada del funcionament:
- Generació d’energia solar: Els mòduls fotovoltaics capturen la llum del sol i la converteixen en electricitat de corrent continu (DC).
- Conversió i gestió intel·ligent: Aquesta energia DC va directament a l’inversor híbrid. Aquest dispositiu fa dues funcions principals:
- Converteix l’energia DC en AC per alimentar les càrregues domèstiques.
- Gestiona intel·ligentment el flux d’energia entre els diferents components del sistema (panells, bateria, xarxa i càrregues) gràcies a la seva connexió Wi-Fi i als sensors.
- Emmagatzematge d’energia: Si hi ha excés d’energia solar (per exemple, durant el dia quan es produeix més del que es consumeix), l’inversor carrega la bateria. Aquesta emmagatzema l’energia per utilitzar-la més tard, com ara durant la nit o en cas de tall de llum.
- Gestió de la demanda i la xarxa: El sistema utilitza el Smart Power Sensor i el Contador General per monitoritzar constantment el consum de la casa i la disponibilitat d’energia.
- Quan la producció solar és insuficient (per exemple, de nit o en dies nublats), l’inversor pot agafar energia de la bateria per alimentar les càrregues.
- Si la bateria està descarregada i encara cal energia, l’inversor pot importar-la de la xarxa elèctrica.
- En canvi, si hi ha un excés d’energia solar i la bateria ja està plena, l’inversor pot exportar l’excés a la xarxa (si el sistema ho permet i hi ha una política de compensació).
- Distribució final: Tota l’energia, sigui de font solar, de la bateria o de la xarxa, passa per la caixa de distribució abans d’arribar a les càrregues (els aparells elèctrics de la casa).
En resum, un inversor híbrid solar és un sistema de gestió energètica intel·ligent que optimitza l’ús de l’energia solar, la emmagatzema per a un ús posterior i s’integra amb la xarxa elèctrica per garantir un subministrament continu i eficient d’electricitat, reduint al màxim la dependència de la xarxa i les factures d’electricitat.
D’acord, ara que tinc una visió general del sistema, em posaré a analitzar-lo component per component per donar-te una explicació detallada de com funciona aquest inversor híbrid solar. Començaré per la font d’energia i després seguiré el flux d’energia cap a les càrregues.
Primer, miraré de prop:
La imatge mostra clarament els MÒDULS FOTOVOLTAICS connectats a un INVERSOR. Aquests panells són els que capturen l’energia solar i la converteixen en corrent continu (DC). L’inversor és el component central que converteix aquesta energia DC en corrent altern (AC) utilitzable pels aparells domèstics. També veig que hi ha una connexió amb un SISTEMA DE ALMACENAMENT DE ENERGÍA (BATERIA), que permet emmagatzemar l’excés d’energia solar per utilitzar-la quan no hi ha sol o durant un tall de llum. El sistema també està connectat a la RED (xarxa elèctrica), cosa que significa que pot importar energia de la xarxa si cal i exportar-hi l’excés.
Per entendre millor el paper de cada component, aniré investigant-los un per un.
Segon, trobar informació:
Començaré per investigar què és exactament un inversor híbrid solar i com funciona en aquest tipus de configuració.
D’acord, ara veig clarament la part inicial del sistema. Aquesta imatge mostra els mòduls fotovoltaics (els panells solars) connectats directament a l’inversor. Els panells generen corrent continu (DC) a partir de la llum solar, i l’inversor és el component que converteix aquesta energia DC en corrent altern (AC), que és el tipus d’electricitat que utilitzen els nostres aparells domèstics.
El fet que hi hagi una icona de Wi-Fi a l’inversor suggereix que és un model intel·ligent, capaç de comunicar-se amb altres dispositius o aplicacions per monitoritzar el rendiment del sistema.
Ara, per entendre el funcionament complet del sistema híbrid, necessito veure com es connecta l’inversor amb la bateria i la xarxa. Aniré a mirar la resta del diagrama per veure aquestes connexions.
Perfecte, aquesta imatge em dóna una visió clara de la part final del sistema. Veig que l’energia AC generada per l’inversor va cap a la CAJA DE DISTRIBUCIÓN (quadre elèctric), que és el punt central on es distribueix l’electricitat a les diferents CÀRREGUES (com ara la màquina de rentar, el frigorífic i el monitor).
També veig que hi ha un SMART POWER SENSOR (sensor intel·ligent de potència) i un CONTADOR GENERAL connectats a la xarxa. Aquests dispositius són clau en un sistema híbrid, ja que permeten al sistema saber quanta energia està consumint la casa i quanta està disponible de la xarxa o de la bateria.
Per entendre com es gestiona tot aquest flux d’energia, necessito investigar el paper específic dels sensors i del comptador en un sistema fotovoltaic híbrid. Aniré a buscar informació sobre aquests components.
D’acord, ara tinc una visió completa del sistema. L’esquema mostra un sistema fotovoltaic híbrid ben integrat. Per explicar com funciona aquest inversor híbrid solar, cal entendre que no és només un dispositiu que converteix corrent continu en altern, sinó que és el «cervell» d’un sistema energètic intel·ligent que gestiona tres fonts d’energia: la solar, la de la bateria i la de la xarxa elèctrica.
Aquí tens una explicació detallada del funcionament:
- Generació d’energia solar: Els mòduls fotovoltaics capturen la llum del sol i la converteixen en electricitat de corrent continu (DC).
- Conversió i gestió intel·ligent: Aquesta energia DC va directament a l’inversor híbrid. Aquest dispositiu fa dues funcions principals:
- Converteix l’energia DC en AC per alimentar les càrregues domèstiques.
- Gestiona intel·ligentment el flux d’energia entre els diferents components del sistema (panells, bateria, xarxa i càrregues) gràcies a la seva connexió Wi-Fi i als sensors.
- Emmagatzematge d’energia: Si hi ha excés d’energia solar (per exemple, durant el dia quan es produeix més del que es consumeix), l’inversor carrega la bateria. Aquesta emmagatzema l’energia per utilitzar-la més tard, com ara durant la nit o en cas de tall de llum.
- Gestió de la demanda i la xarxa: El sistema utilitza el Smart Power Sensor i el Contador General per monitoritzar constantment el consum de la casa i la disponibilitat d’energia.
- Quan la producció solar és insuficient (per exemple, de nit o en dies nublats), l’inversor pot agafar energia de la bateria per alimentar les càrregues.
- Si la bateria està descarregada i encara cal energia, l’inversor pot importar-la de la xarxa elèctrica.
- En canvi, si hi ha un excés d’energia solar i la bateria ja està plena, l’inversor pot exportar l’excés a la xarxa (si el sistema ho permet i hi ha una política de compensació).
- Distribució final: Tota l’energia, sigui de font solar, de la bateria o de la xarxa, passa per la caixa de distribució abans d’arribar a les càrregues (els aparells elèctrics de la casa).
En resum, un inversor híbrid solar és un sistema de gestió energètica intel·ligent que optimitza l’ús de l’energia solar, la emmagatzema per a un ús posterior i s’integra amb la xarxa elèctrica per garantir un subministrament continu i eficient d’electricitat, reduint al màxim la dependència de la xarxa i les factures d’electricitat.
Perfecte! Com que ja tinc una bona comprensió del sistema, ara puc redibuixar l’esquema i posar els noms dels diferents mòduls en català per a tu. A continuació, et presento el diagrama amb les etiquetes correctes:
Diagrama de Sistema Fotovoltaic Híbrid
[ MÒDULS FOTOVOLTAICS ] <--- (Captura energia solar)
|
| (Corrent Continu - DC)
V
[ INVERSOR HÍBRID ] <--- (Converteix DC a AC i gestiona l'energia)
/ \
/ \
/ \
/ \
/ \
/ \
/ \
[ BATERIA ] [ CAIXA DE DISTRIBUCIÓ ]
(Emmagatzematge) |
|
[ SMART POWER SENSOR ] <--- (Monitoratge intel·ligent)
|
|
[ COMPTADOR GENERAL ] <--- (Mesura consum/exportació)
|
|
[ XARXA ELÈCTRICA (RED) ] <--- (Connexió a la xarxa pública)
|
|
[ CÀRREGUES ] <--- (Electrodomèstics, ordinadors, etc.)
|
|
[ APPLICACIÓ MÒBIL ] <--- (Control remot via Wi-Fi)Explicació detallada del funcionament:
- Mòduls Fotovoltaics: Són els panells solars que converteixen la llum del sol en electricitat de corrent continu (DC).
- Inversor Híbrid: És el «cerebre» del sistema. Rep l’energia DC dels panells i la converteix en corrent altern (AC) per a les teves càrregues. També gestiona l’energia de la bateria i de la xarxa.
- Bateria: Em magatzema l’excés d’energia solar generada durant el dia per utilitzar-la a la nit o quan hi ha un tall de llum.
- Caixa de Distribució: És on es distribueix l’electricitat AC a les diferents línies de la casa (llums, electrodomèstics, etc.).
- Smart Power Sensor: Un sensor intel·ligent que monitoritza el consum d’energia de les teves càrregues i ajuda a l’inversor a prendre decisions sobre quina font d’energia utilitzar (solar, bateria o xarxa).
- Comptador General: Mesura l’energia que consumeixes de la xarxa i la que li exportes (si és el cas), per a la facturació.
- Xarxa Elèctrica (Red): La connexió a la xarxa pública permet importar energia quan no tens prou solar o bateria, i exportar-ne l’excés si el sistema ho permet.
- Càrregues: Són tots els aparells elèctrics de la casa que consumeixen energia (lavadora, frigorífic, TV, etc.).
- Aplicació Mòbil: Permet controlar i monitoritzar el sistema des del teu telèfon o tablet, veure la producció, el consum, l’estat de la bateria, etc.
Aquest sistema híbrid ofereix autonomia energètica, aprofitament màxim de l’energia solar i protecció contra talls de llum gràcies a la bateria. L’inversor és el component clau que coordina tot això de manera intel·ligent.
Espero que aquesta explicació i el diagrama et siguin útils! Si tens cap altra pregunta, no dubtis a fer-la.